Analysis of Variance (ANOVA) is a statistical methodology used to analyze the mean differences when there are more than two groups for one independent variable as in a One-Way ANOVA, more than two independent variables in a Multiple ANOVA, such as Two-Way ANOVA.
The example below calculates the Analysis of Variance (ANOVA) using the raw data. ANOVA can be calculated using just the means assuming equal sample sizes as in this example. However, there are several assumptions using the means-based approach that may be violated with your data:
The data involved must be interval or ratio level data.
The populations from which the samples were obtained is normally distributed.
The samples must be independent.
The variances of the populations must be equal (i.e., homogeneity of variance).
10.1.1 A Concrete Example
The following dataset contains 18 values for three groups in a one-way ANOVA.
Group
Value
Deviation from Group Mean
Squared Deviation from Group Mean
A
1
-1
1
A
2
0
0
A
3
1
1
A
1
-1
1
A
2
0
0
A
3
1
1
B
4
-1
1
B
5
0
0
B
6
1
1
B
4
-1
1
B
5
0
0
B
6
1
1
C
1
-1
1
C
2
0
0
C
3
1
1
C
1
-1
1
C
2
0
0
C
3
1
1
an <-data.frame(group =c("A","A","A","A","A","A","B","B","B","B","B","B","C","C","C","C","C","C"),value =c(1,2,3,1,2,3,4,5,6,4,5,6,1,2,3,1,2,3))res <-lm(data = an, value ~ group)anova(res)
Analysis of Variance Table
Response: value
Df Sum Sq Mean Sq F value Pr(>F)
group 2 36 18.0 22.5 3.052e-05 ***
Residuals 15 12 0.8
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
res <-aov(data = an, value ~ group)summary(res)
Df Sum Sq Mean Sq F value Pr(>F)
group 2 36 18.0 22.5 3.05e-05 ***
Residuals 15 12 0.8
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
p <-pf(22.5, 2, 15, lower.tail = F)p
[1] 3.051758e-05
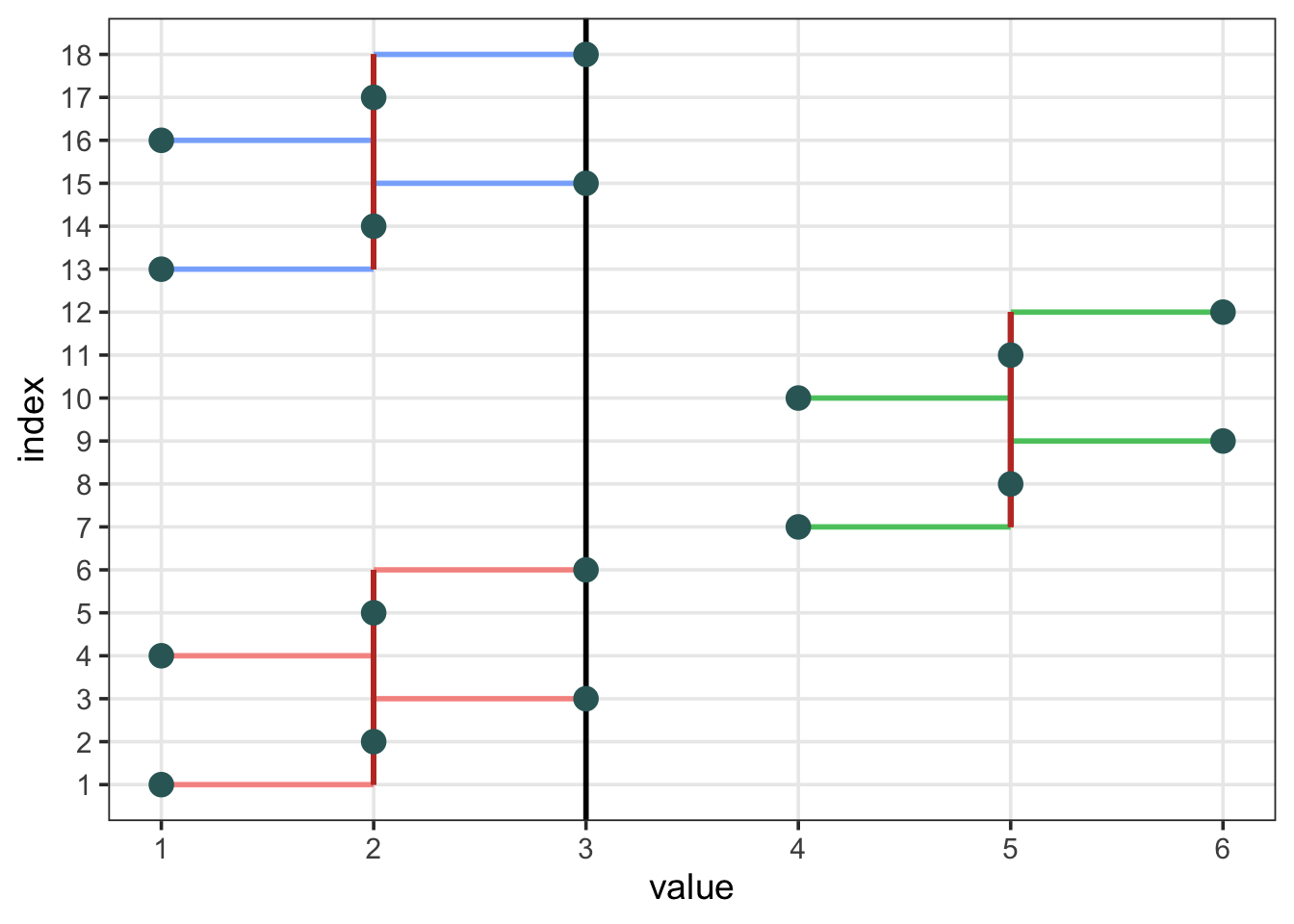
10.1.2 A Visual Example
an <-data.frame(group =c("A","A","A","A","A","A","B","B","B","B","B","B","C","C","C","C","C","C"),value =c(1,2,3,1,2,3,4,5,6,4,5,6,1,2,3,1,2,3))an <- an %>%mutate(index =as.numeric(rownames(.))) %>%group_by(group) %>%mutate(grp_m =mean(value)) %>%mutate(grp_min =min(value)) %>%mutate(grp_max =max(value)) %>%mutate(idx_min =min(index)) %>%mutate(idx_max =max(index)) %>%ungroup()an
# A tibble: 18 × 8
group value index grp_m grp_min grp_max idx_min idx_max
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 A 1 1 2 1 3 1 6
2 A 2 2 2 1 3 1 6
3 A 3 3 2 1 3 1 6
4 A 1 4 2 1 3 1 6
5 A 2 5 2 1 3 1 6
6 A 3 6 2 1 3 1 6
7 B 4 7 5 4 6 7 12
8 B 5 8 5 4 6 7 12
9 B 6 9 5 4 6 7 12
10 B 4 10 5 4 6 7 12
11 B 5 11 5 4 6 7 12
12 B 6 12 5 4 6 7 12
13 C 1 13 2 1 3 13 18
14 C 2 14 2 1 3 13 18
15 C 3 15 2 1 3 13 18
16 C 1 16 2 1 3 13 18
17 C 2 17 2 1 3 13 18
18 C 3 18 2 1 3 13 18
p <- an %>%ggplot(aes(x = value, y = index))p <- p +geom_segment(aes(x = value, xend = grp_m, y = index, yend = index, color = group), size =1, alpha = .75)
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.
p <- p +geom_segment(aes(x = grp_m, xend = grp_m, y = idx_min, yend = idx_max), size =1, color ="#C0392B", alpha = .75)p <- p +geom_vline(xintercept =mean(an$value), size =1, color ="black")p <- p +geom_point(color ="#336666", size =4)p <- p +theme_classic()p <- p +scale_x_continuous(limits =c(1,6), breaks =c(1:6))p <- p +scale_y_continuous(limits =c(1,18), breaks =c(1:18))p <- p +theme_bw(base_size =14)p <- p +theme(panel.grid.minor =element_blank())p <- p +guides(color =FALSE)
Warning: The `<scale>` argument of `guides()` cannot be `FALSE`. Use "none" instead as
of ggplot2 3.3.4.
You may also see some terminology such as Treatments and Error instead of between groups and within groups. Treatments in interchangeable with between groups, and error is interchangeable with within groups.
10.1.3.1 Step 1: Define the Hypotheses
The Null Hypothesis () states there are no significant differences between group means (), whereas the Alternative Hypothesis () suggests there is at least one significant difference between group means.
10.1.3.2 Step 2: Calculate the Grand Mean () and the Group Means ()
The Grand Mean () is the mean across the dataset, ignoring group membership:
Where:
is the Grand Mean, the mean of all values in the dataset.
is the sum of all the values in the dataset, starting from (the first value) for all values .
represents each individual values.
means to divide the sum of the individual values in the dataset by the number of values.
Simply, we’re going to sum () all the values () in the dataset and divide by the number of values ().
The Group Means () are the mean within each group:
Where:
is the Group Mean for the th group.
represents each individual value within the th group.
represents the number of observations within the th group.
is the sum of all the values within the th group.
Dividing by finds the average of these observations within that specific group.
10.1.3.3 Step 3: Calculate the Sum of Squares Between ()
The Sum of Squares Between () measures the variability between the group means.
Where:
is the Sum of Squares Between.
is each individual group.
is the total number of groups
is the number of values in each group .
is the Group Mean for group .
is the Grand Mean.
is the sum of all the squared Group Mean deviations from the Grand Mean, starting from (the first value) for all groups .
Simply, the Sum of Squares Between () is the sum () of the squared () deviations of each Group Mean () from the Grand Mean (), squared (), times the number values in each group ().
10.1.3.4 Step 4: Calculate the Sum of Squares Within ()
The Sum of Squares Within () measures the variability within each group.
Where:
is the Sum of Squares Within.
represents individual data points.
is the mean of the data in group (j.
Simply, the Sum of Squares Within () is the sum () of the squared () deviations () of each individual value () from its Group Mean .
10.1.3.5 Step 5: Calculate the Degrees of Freedom (DF)
Degrees of Freedom are
Degrees of Freedom for Between Groups:
Degrees of Freedom for Within Groups:
Where:
is the number of groups.
is the total number of values in the dataset.
10.1.3.6 Step 6: Calculate the Mean Squares (MS)
Mean Square Between:
Mean Square Within
Where:
is the Mean Square Between.
is the Mean Square Within
is the Sum of Squares Between.
is the Sum of Squares Within.
is the degrees of freedom for the Sum of Squares Between.
is the degrees of freedom for the Sum of Squares Within.
10.1.3.7 Step 7: Calculate the F-Statistic ()
The F-statistic is the ratio of the mean square between to the mean square within.
Where:
is the F-statistic.
is the Mean Square Between.
is the Mean Square Within.
Simply, the obtained or observed F-Value () is the ratio of variance between groups () to the variance within groups ()
10.1.3.8 Step 8: Find the () and Compare to ()
Leveraging an F-table, and the significance level (), calculate the value:
In R, pf(F, df_between, df_within, lower.tail = F)
In Excel, =F.DIST.RT(F, df_between, df_within)
If the () is greater than (), the null hypothesis () is rejected, meaning there is some difference between groups, although this does not specific which group mean is significantly different.
If the () is less than (), the null hypothesis () has been failed to be rejected, or is retained, meaning there are no significant differences among the group means.