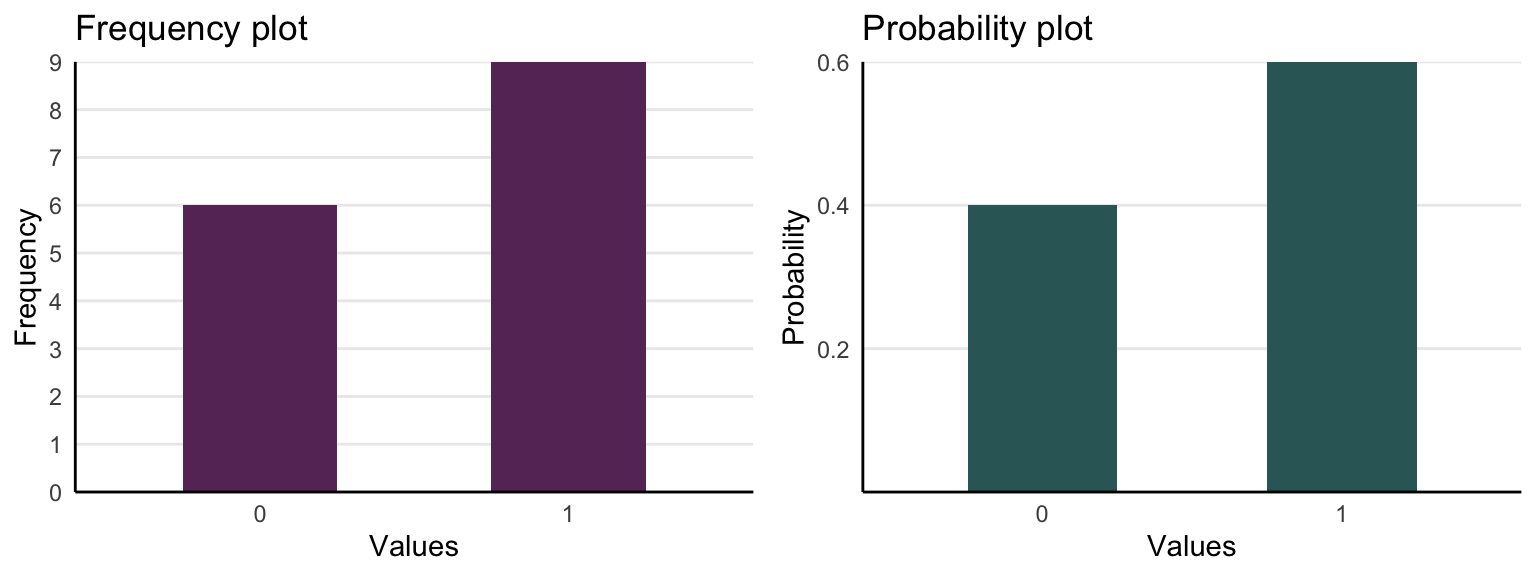
Distributions are fundamental to psychological statistics. This section will overview these fundamentals, building from the simplest distributions and adding complexity one layer at a time, but will reserve discussions statistical distributions for later chapters. First, a distribution is a set of possible values and the frequency of those values. For example, consider 15 students answering a single test question correctly. The possible values are incorrect (0 points) or correct (1 point). Suppose 6 students answered the question incorrectly and 9 answered the question correctly, these are the frequencies of the possible values 0 and 1. A frequency_distribution is simply the spread of the observed values between the possible values. Dividing the number of students who answered the question correctly (9) by the total number of students (15) gives the probability (.6) of a correct answer. Therefore, probabilities are values between 0 and 1 that describe the chance of observing a particular value. Figure 1.1 shows the representation this example as both frequencies and probabilities.
The simplest probability distribution for only one potential outcome is the bernoulli_distribution which is used in the example above to decribe the probability of one potential outcome occurring. This is the first discrete_distribution, meaning a distribution of an event or events that categorically did or did not occur. From the Bernoulli distribution, suppose instead of one trial or test question we wanted to know the probability of correctly answering multiple questions correctly. The binomial_distribution describes the possibility of observing some outcome more than one time. While the test question example is imperfect at the Binomial distribution as it describes the probability of observing an identical trial, let’s assume these test questions are identical for the sake of a simple example. With two questions, and assuming an equal chance of getting either test question correct, the Binomial distribution below shows a probability (p) of .25 for getting only one question correctly, a probability of .5 for getting one of the questions correctly, and a .25 probability of getting both questions correctly. Use the sliders in the interactive figure below to explore how changing the number of trials or the probability of success changes the shape of the distribution. If you keep the probability of success and slide the number of trials all the way to the right will see a distribution that may look familiar to you and is a very rough approximation of a continuous distribution to be discussed later.
The Poisson distribution models the probability of a given number of events occurring in a fixed interval of time or space when these events happen with a known constant rate, (), and independently of each other. It is particularly useful for rare events. For example, the Poisson distribution can be applied to predict the number of cars passing through a toll booth in an hour, given an average rate, or the number of phone calls received by a call center per minute. The key characteristic is that the events occur at a steady average rate, but the actual count of events varies unpredictably around that rate. The mean and variance of the distribution are both equal to (), reflecting the spread and central tendency of event counts over time or space.
1.3 Working Section (Do not use!!)
While distributions describe the spread of values, generally, psychological statistics focus on probability distributions.
Possible values in distributions are usually categorized as discrete, which describe distinct categories or counts,
This fundamental theory of probability is also applied to probability distributions.
What Are Probability Distributions?
A probability distribution is a statistical function that describes all the possible values and probabilities for a random variable within a given range.
A probability distribution is a mathematical function that describes the likelihood of different possible outcomes in a random experiment or process. It assigns probabilities to each possible event in the sample space.
Probability distributions are focused on estimating the probability of an event occurring. Examples include the normal distribution, which is often used to describe continuous data, and the binomial distribution, which is used for discrete data. Most often in psychology, the ultimate goal of learning distributions is to get to the normal distributions, but it’s important to learn the discrete distributions as all probability distributions are related, so learning the basics sets a solid foundation for later.
1.4 Discrete Distributions
Binomial Distribution: This is used to model the number of successes in a fixed number of independent Bernoulli trials. It’s a discrete distribution that describes the number of successes in a fixed number of trials (n) with a constant probability of success (p).
Poisson Distribution: Models the number of events occurring in a fixed interval of time or space, given a constant average rate of occurrence.
The simplest distribution is a Bernoulli distribution, which represents a single trial with only two possible outcomes: success or failure with a fixed probability of success (p). This distribution can be used to model situations where there is a binary outcome, such as whether an employee attended work today (success) or not (failure).
[Visualization here]
The Binomial distribution extends the Bernoulli distribution by modeling the number of successes in a fixed number of independent Bernoulli trials. For example, this distribution could be used to count the number of employees out of a sample who successfully complete a training program. This helps in assessing the effectiveness of training programs across a group of employees.
The Poisson distribution is used for modeling the number of events occurring within a fixed interval of time or space. This distribution is useful for understanding the frequency of certain types of events over time, such as the number of accidents in a workplace over the course of a year.
1.5 Continuous Distributions
Normal Distribution: The binomial distribution approximates the normal distribution as the number of trials (n) becomes large. This is known as the “normal approximation to the binomial.”
t-Distribution: The t-distribution is derived from the normal distribution and is used for inference about a population mean when the sample size is small or when the population standard deviation is unknown.
Chi-Square Distribution: The chi-square distribution is related to the normal distribution and is used in hypothesis testing for categorical data, such as goodness-of-fit tests or tests of independence.
F-Distribution: The F-distribution is the ratio of two independent chi-square distributions and is used in ANOVA to compare variances of two or more groups.